Contexte Dans le cadre de mes activités avec le Parti Ꝓirate Rhône-Alpes pour la mise en place globale des données ouvertes à Lyon, je suis amené à rencontrer de nombreux élus, gestionnaires de collectivités, et responsables d’entreprises. Si la première étape (rassemblement de personnes au fait des […]
Mot-clé - bilan
dimanche 11 décembre 2011
Bilan de début de parcours sur la mise en place des données ouvertes à Lyon
dimanche 11 décembre 2011. Idées et réflexions
jeudi 19 août 2010
Les chercheurs, la voiture et le plot : une réflexion sur l'usage de la force brute
jeudi 19 août 2010. Idées et réflexions
Au LIRIS, nous n'hésitons à pas donner de notre personne pour résoudre les problèmes. Surtout quand il ne sont pas du domaine de nos spécialités. Laissez-moi vous raconter une histoire. L'histoire Il était une fois, un groupe de chercheurs qui sortaient de leur laboratoire afin de rentrer chez-eux. […]
mercredi 9 juin 2010
Comparaison appliquée des principaux outils web de calcul d'itinéraire
mercredi 9 juin 2010. Informatique
J’ai eu récemment à faire un déplacement sur Vienne (Isère). Étant un villeurbannais sans voiture, mon choix s’est naturellement porté sur le train pour m’y rendre. Ne connaissant pas du tout Vienne, je me suis tourné vers les outils gratuits du web pour organiser le trajet depuis la gare de Vienne […]
samedi 5 juin 2010
Valorisation de mon travail
samedi 5 juin 2010. Idées et réflexions
Pour la quatrième fois, une de mes photos a été reprise pour illustrer un article. Je ne sais pas si je dois désormais me demander si je suis meilleur photographe que chercheur, mais je pense qu'il y a peut être une piste à explorer ;) Plus sérieusement, j'estime que les facteurs étant à l'origine […]
mardi 13 octobre 2009
BiblioCNRS, un FAIL en perspective
mardi 13 octobre 2009. Trouvailles et lectures
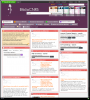
Avant les grandes vacances, je me suis retrouvé embarqué (je ne sais plus comment) pour betatester le futur service unifié de recherche bibliographique du CNRS : BiblioCNRS. Et bien moi, je vous le dis, c'est pas gagné. À base de Netvibes, le portail a la pesanteur d'un mammouth farci à l'herbe […]
jeudi 30 juillet 2009
Pourquoi je ne crois pas (encore) en la trace modélisée
jeudi 30 juillet 2009. Idées et réflexions
Non, non, ne hurlez pas; je vous vois venir avec vos mais qu'est-ce qu'il va encore nous inventer cette fois-ci ? :) Lisez, vous allez voir, ça va vous intéresser. Avant-propos Je travaille depuis maintenant un bon moment à mettre en place une partie de nos idées sur les traces, concernant la […]
mardi 12 septembre 2006
Participation au 2006 HCI Workshop on Computer Assisted Recording, Pre-Processing, and Analysis of User Interaction Data
mardi 12 septembre 2006. Compte-rendus de déplacement

Je viens de participer au 2006 HCI Workshop on Computer Assisted Recording, Pre-Processing, and Analysis of User Interaction Data, in co-operation with ACM. Voici ce que j'en retiens à chaud. Informations date : mardi 12 septembre 2006 appel à participation site web organisateur : […]




{kind=link}
{kind=link}